AI Assistant for Interviews: How It Works and When to Use One?
If you are evaluating an AI assistant for interview processes at your organization, the market has already made the decision easier by eliminating the "whether" question. About 87% of companies use some form of AI recruiting software as of 2025. The real question is which tool fits your hiring volume, your technical role mix, and your compliance obligations - and whether the vendor you are talking to has actually built for technical hiring or just bolted a coding question onto a generic screening product.
This guide skips the basics. It is written for HR generalists and talent leaders who are ready to evaluate tools, justify investment to stakeholders, and ask the right questions before signing a contract.
What Is an AI Assistant for Interviews?
Definition and Core Concept
An AI assistant for interviews is any software that uses machine learning, natural language processing, or automated scoring to replace or support a step in candidate evaluation. The category ranges from a chatbot that handles scheduling to a full AI interview evaluation tool that conducts a structured technical conversation and returns a scorecard with no human involvement. The core promise is consistent: hand the repetitive, high-volume parts of interviewing to a system that applies the same standard to every candidate, every time.
The AI recruitment market stood at USD 596.16 million in 2025 and is forecast to reach USD 860.96 million by 2030, with 92% of organizations claiming measurable benefits.
Types of AI Interview Assistants
Not every tool in this category solves the same problem, and conflating them is how procurement mistakes happen.
%20(1).png)
A standalone virtual interview assistant may handle scheduling without evaluating skills at all. A smart interview assistant that only scores behavioral responses is not a substitute for a code evaluation engine. The tools that deliver the most value to technical hiring teams are AI candidate interviewers and end-to-end platforms that combine automated screening, structured interviews, and analytics in one place.
HackerEarth falls into that final category. Its platform includes AI-powered technical assessments, an AI Screener, an AI Interviewer for end-to-end structured interviews, and FaceCode, a live coding interview platform with AI-assisted insights and advanced proctoring.
How Does an AI-Powered Interview Tool Work?
The Technology Behind AI Interview Software
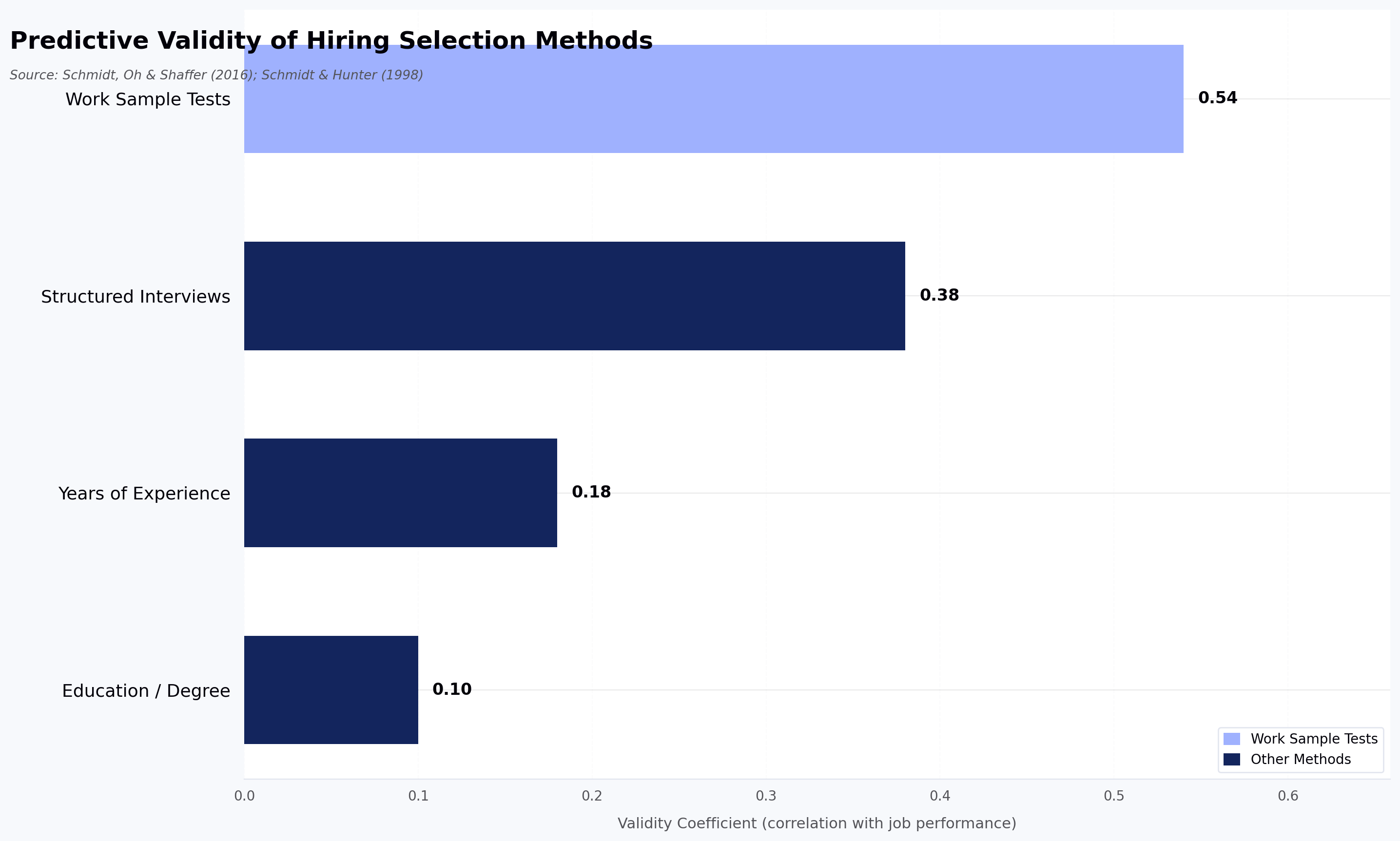
The plumbing matters here because it determines what the tool can actually evaluate. Most platforms combine natural language processing for text and speech analysis, machine learning models for scoring against benchmarks, and a code execution engine that runs submitted code against test cases. Platforms that lack that last component cannot genuinely evaluate engineering candidates. Surveys and multiple choice questions are not code evaluation.
NLP accounted for 35.09% of AI recruitment revenue in 2024, while robotic process automation is projected to grow at 13.30% per year as scheduling and administrative tasks shift to automation.HackerEarth's assessments cover 1,000+ skills and 40+ programming languages across a library of 40,000+ problems, including real-world project simulations that evaluate code quality, logic, efficiency, and technical depth.
Step-by-Step: What Happens During an AI-Assisted Interview
The workflow for a well-designed automated interview assistant runs roughly like this: a job requisition triggers question selection and rubric configuration; the AI generates role-specific questions or selects from a validated library; the candidate completes the interview on their own schedule; the system processes responses in real time, executing code and analyzing verbal answers; and the platform returns a structured scorecard for human review. HackerEarth's AI Interview Agent can tailor interviews for architecture, coding, and system design by role and seniority level, customizing questions based on the job description and the candidate's resume.
The final decision stays with a human. That is not just good practice. In most regulated jurisdictions, it is a legal requirement.
AI Scoring vs. Human Scoring
Human interviewers score the same candidate differently depending on who is in the room, what mood they are in, and whether the candidate reminds them of someone they already hired. AI scoring does not fix everything, but it applies one rubric to every candidate without variation. Coding interview AI tools cut grading time by more than 50% while increasing rubric adherence, and video interview summarization reduces review time per candidate by approximately 60%.
Key Benefits of Using an AI Interview Assistant
Drastically Reduced Time-to-Hire
Speed is the most immediate return, and the numbers are not marginal. AI tools can reduce time-to-hire by 50%. Each additional day in the hiring cycle increases cost per hire by an average of $98, and 57% of candidates lose interest in companies that take longer than two weeks to respond. An AI hiring assistant processes hundreds of candidates simultaneously and surfaces only the top performers for human review, which means your engineering team is not spending its afternoons on first-round phone screens.
More Consistent and Objective Candidate Evaluation
Consistency is also a legal asset, not just an operational one. When you cannot explain why one candidate scored differently from another, you have a defensibility problem. 68% of recruiters say AI could remove biases from hiring, and nearly half of hiring managers admit to having some form of bias that negatively impacts interviews.A well-configured AI interview evaluation tool does not eliminate bias, but it makes evaluation criteria explicit, auditable, and consistent across every interviewer and every location.
Scalability and Data-Driven Decisions
The math on manual technical hiring does not work at scale. Hiring an engineer requires approximately 14 more interview hours than filling a non-technical position, and the average cost per hire has reached $4,700, with senior technical hires often exceeding $28,000. An automated interview assistant absorbs the volume that would otherwise require three times the recruiter headcount. And every session generates structured data: over time, advanced analytics can predict job performance with 78% accuracy and retention with 83% accuracy.
When Should You Use an AI Interview Assistant?
High-Volume Technical Recruitment
If your team is processing more than fifty technical candidates per month, the first-round interview is your bottleneck. An AI-powered interview tool with a real code evaluation engine removes it without sacrificing signal quality. HackerEarth has assessed over 5.5 million developers and supported 6,000 companies with 43,000 coding tests, which means the benchmarks reflect real population-level data rather than a proprietary rubric someone built last quarter.
Standardizing Interviews Across Distributed Teams and Reducing Bias
These two problems share the same root cause: different people applying different standards. A candidate evaluated in Singapore should clear the same bar as one evaluated in London. An AI candidate interviewer enforces that by making the rubric the same regardless of who is running the process. 72% of companies using AI interview tools report a reduction in hiring bias, and 58% say AI-powered interviews have helped them achieve greater diversity.
When NOT to Use AI (Honest Take)
For highly senior hires, small candidate pools, or roles where cultural judgment and leadership presence are primary criteria, AI is a support tool at best. 74% of candidates still prefer human interaction for final decisions. Use AI for early and mid-funnel screening. Keep humans at the close.
How to Evaluate and Choose the Right AI Interview Software
Must-Have Features Checklist
Before requesting a demo, run every vendor against this list. Gaps here are not roadmap items to accept on faith.
- AI-powered question generation and a validated question library: Role-specific, not generic.
- Automated scoring with transparent rubrics: If you cannot see what drove a score, you cannot defend it to a candidate or a regulator.
- Code evaluation engine: Non-negotiable for technical roles. The system must execute code, not just score a written description of code.
- ATS and HRIS integration: Native sync with Greenhouse, Lever, Workday, or your existing stack. Manual data entry at this stage defeats the purpose.
- Anti-cheating and proctoring: Browser lockdown, plagiarism detection, and identity verification for async assessments.
- Bias auditing and fairness reporting: Demographic outcome monitoring is no longer optional given the regulatory landscape.
- Analytics dashboard with exportable reports: You need to measure what is working without filing a support ticket.
- Customization for role-specific criteria: One rubric for all engineering roles is not a rubric. It is a guess.
Questions to Ask Vendors Before You Buy
How was your AI model trained, and on what data? Historical hiring data that reflects past discrimination will reproduce it.
What bias mitigation measures are built in? Ask for specifics: demographic parity testing, outcome analysis, validation methodology.
Can we customize scoring rubrics per role? If the answer is no, you are buying a screening tool, not a technical interview platform.
How does this integrate with our existing ATS? Get the specific integration method and the list of supported versions before the demo ends.
What compliance certifications do you hold? SOC 2 Type II, ISO 27001, GDPR, and NYC Local Law 144 support are the minimum checkboxes.
What support and onboarding do you provide? Time-to-value depends almost entirely on implementation quality, not the feature list.
Why HR Teams Choose HackerEarth for AI-Powered Technical Interviews
Most general-purpose AI interview tools were designed for behavioral hiring and added technical evaluation later. That sequence produces a weak code evaluation layer on top of a survey engine. HackerEarth was built the other way around.
The AI Screener evaluates candidates with auto-graded coding tests, AI evaluations, and personality assessments, ensuring a consistent hiring bar across teams. The AI Interviewer conducts structured role-specific conversations that assess both technical competence and communication. FaceCode supports live coding interviews with an integrated IDE, pair-programming workflows, AI-assisted insights, and panels for up to five interviewers.
Where HireVue focuses primarily on behavioral video assessment and TestGorilla covers broad skills testing, HackerEarth gives technical hiring teams the complete stack: automated screening, structured AI interviewing, live collaborative coding, and analytics in one platform backed by over a decade of developer evaluation data.
Real-World Use Cases: AI Interview Assistants in Action
Campus and University Hiring at Scale
University hiring is the use case where the ROI argument writes itself. Hundreds of candidates, a two-to-four-week window, limited recruiter bandwidth, and a legal obligation to treat every applicant fairly. An AI interview platform runs all candidates through the same structured technical screen simultaneously. The team reviews ranked, scored results and moves the top cohort forward before the recruiting season closes. A BCG survey of chief human resources officers in 2024 found that 92% of organizations using AI in HR report real benefits, with talent acquisition as the top use case.
Remote-First Technical Hiring
A virtual interview assistant solves the time zone problem that makes remote technical hiring logistically brutal. Candidates in any geography complete a structured evaluation without waiting for a senior engineer in another region to be free. 70% of recruiters using AI interview tools say that 24/7 availability has significantly expanded their talent pool. For distributed teams, this is not a convenience. It is how global hiring becomes operationally viable.
Diversity Hiring Initiatives
A well-configured AI interview evaluation tool makes bias visible rather than invisible. Consistent rubric application reduces evaluator-level variation, and demographic outcome reporting lets teams catch and correct patterns before they become hiring decisions. AI-driven diversity sourcing has improved representation in shortlists by 8 to 14% when properly configured and monitored. The operative phrase is "properly configured." AI does not produce fair outcomes by default. It produces auditable ones, which gives you something to act on.
Addressing Common Concerns About AI in Interviews
"Will AI Make Hiring Feel Impersonal?"
The candidates who have actually completed a well-designed AI interview are less concerned about this than those who have not. In a large-scale field experiment at the University of Chicago's Booth School of Business involving approximately 70,000 candidates, 78% preferred AI interviews over human ones, and 71% of candidates in the AI-led group gave positive feedback compared to 52% in the human-led group. The impersonality concern is real for a poorly designed process. For a well-designed one with clear communication and a human decision at the end, most candidates adapt quickly.
"Is AI Interview Software Biased?"
It can be, and any vendor who says otherwise is not worth your time. A 2025 University of Washington study found that certain AI screening tools favored white-associated names in 85.1% of cases. The solution is not to avoid AI but to demand transparent rubrics, demographic outcome reporting, and regular independent bias audits. Ask HackerEarth or any vendor you are evaluating to show you specifically how they monitor for and report on scoring disparities across candidate groups.
"What About Legal Compliance?"
This is moving fast and the risk is real. NYC Local Law 144 requires annual independent bias audits of automated employment decision tools, public disclosure of results, and advance candidate notification, with penalties up to $1,500 per violation. The EU AI Act classifies AI systems used in hiring as high-risk, requiring transparency, documentation, and human oversight. More than ten US states are enacting or drafting similar legislation. Before you deploy any tool, confirm which regulations apply to your hiring locations and what the vendor provides to support compliance documentation.
"How Do Candidates Feel About AI Interviews?"
Mixed, with an important caveat. In a Gartner 3Q 2025 survey of 2,901 candidates, 68% said they prefer human interactions over AI. But 79% of candidates want transparency when AI is used in hiring. The discomfort is mostly with surprise, not with AI itself. Tell candidates upfront what the AI evaluates, confirm a human reviews the results, and the drop-off and trust concerns diminish substantially.
The Future of AI Interview Assistants
The next generation of tools is already visible in early deployments. Generative AI is enabling dynamic follow-up questioning rather than fixed sequences. Multimodal assessment is combining coding, verbal explanation, and behavioral signals into a single session. Predictive analytics are improving: advanced models can already predict job performance with 78% accuracy and retention with 83% accuracy. In 2025, skills sought by employers changed 66% faster in occupations most exposed to AI, which means platforms with large, actively maintained question libraries will pull further ahead of those that update quarterly.
HackerEarth's architecture is built for where this is going: a single platform that handles the full technical evaluation workflow while generating the longitudinal data needed to continuously improve hiring decisions.
Conclusion
87% of companies now use AI in their hiring process, up from 30% in early 2024. For technical hiring teams still running manual first-round screens, the gap is no longer just an efficiency problem. It is a competitive one. The candidates you are slow to evaluate are accepting offers from organizations that moved faster.
The right platform depends on your volume, your role mix, and your compliance obligations. If you are hiring engineers at scale, you need a tool built for technical evaluation from the ground up, not a behavioral interviewing platform with a coding question appended.
HackerEarth is that platform. The combination of AI-powered assessment, automated AI interviewing, live coding with FaceCode, and deep analytics gives technical hiring teams a complete workflow rather than a collection of point solutions. See it working on your actual roles before you decide.
See how HackerEarth's AI-powered technical interview platform works in practice. Request a free demo and let the team walk you through the full candidate evaluation workflow for your specific roles.
Ready to cut your technical screening time in half? Start a free trial of HackerEarth Assessments and run your first AI-assisted interview within the week.
Explore HackerEarth's pricing plans for teams of every size. From startup to enterprise, find the right tier for your hiring volume.