How to automate engineering candidate screening
Automated candidate screening — the use of AI and software to evaluate, score, and filter job applicants against predefined criteria without a human reviewing every application — combines resume parsing, skills assessments, AI-scored coding tests, and structured interview screening into one connected workflow that ranks candidates at scale.
If you are a recruiter or hiring manager running an engineering req, the pressure is familiar: a senior backend developer role posts on Monday, hundreds of applications hit the pipeline within a few weeks, and the two technical leads you depend on to screen are already stretched across sprint commitments. Manual resume review takes time most engineering teams do not have — informal industry estimates put resume scan time anywhere from roughly 30 seconds to several minutes depending on role complexity. That means someone on your team has to spend the better part of a workday just getting through the pile once, before any actual evaluation has happened.
Industry research broadly suggests organizations adopting AI-assisted hiring workflows can see reductions in time-to-hire, though specific figures vary by role type and organization size. For engineering hiring, the more useful capability is that automated screening tools can evaluate actual coding ability, not just keywords, which means the candidates who reach your shortlist are more likely to pass the technical interview.
This guide walks through an eight-step process for building an automated screening workflow specifically for engineering roles: from defining criteria and choosing a platform, to running AI-scored coding assessments, implementing fairness safeguards, and continuously improving the system over time.
What automated candidate screening means for engineering roles
Engineering roles benefit from automation more than most other functions because technical skills are directly testable. Whether a candidate can write a working Python function, optimize a SQL query, or architect a REST API can be evaluated in a sandbox environment and scored consistently against a defined rubric. This is categorically different from screening a marketing manager, where judgment, creativity, and communication are harder to quantify before a conversation.
The core components of an automated technical screening workflow:
- Automated resume screening and AI-powered resume parsing that extracts and scores technical qualifications and project experience. (Here, "AI-powered" means natural language processing models trained on resume corpora to recognize skills, roles, and project descriptions; their limits include sensitivity to formatting and to whether the underlying model has been updated for newer technologies.)
- Skills-based coding assessments that run candidates through real problems in a code execution environment
- Automated scoring against role-specific rubrics and benchmark thresholds
- AI interview screening that evaluates problem-solving approach and technical communication
- Candidate ranking and shortlist generation without manual review of every submission
Platforms built specifically for engineering hiring tend to outperform generalist tools because they include developer-focused question libraries, real code execution, and scoring calibrated to engineering skill levels. A platform built for generalist hiring will not give your backend developer candidates a Node.js debugging challenge with proper test-case evaluation.
Step 1: Define role requirements and automated screening criteria
This step produces the rubric that every downstream component — parser, assessment, interview — will score against. A well-structured candidate screening process starts with role definition, not platform configuration. The most common reason technical screening produces weak shortlists is not the tool; it is that the requirements feeding into the tool are vague.
Separate must-haves from nice-to-haves
Collaborate with the engineering lead before configuring any screening parameters. Identify the non-negotiable skills where a gap disqualifies the candidate regardless of everything else, and separate them from preferred qualifications that can be developed on the job.
For a mid-level backend engineer role, a must-have/nice-to-have split might look like this:
| Criterion | Priority | Measurement method |
|---|---|---|
| Python proficiency (intermediate) | Must-have | Coding challenge |
| REST API design | Must-have | Coding challenge |
| SQL querying | Must-have | MCQ + coding task |
| Docker/containerization basics | Must-have | MCQ |
| Kubernetes experience | Nice-to-have | Resume parsing signal |
| GraphQL | Nice-to-have | MCQ |
| System design experience | Nice-to-have (senior bonus) | Project-based task |
Set measurable thresholds
Define pass/fail scoring criteria before the first candidate takes the assessment. Decide upfront: what minimum coding assessment score qualifies a candidate for the next stage? What score range warrants manual review rather than auto-advance or auto-reject?
Setting these thresholds before seeing results prevents score interpretation from drifting between cohorts and creates a defensible record for EEOC compliance purposes. This rubric feeds directly into your platform's auto-advance configuration in Step 7.
Step 2: Choose the right platform for automated candidate screening
Most ATS platforms offer some form of keyword-based resume filtering. That is not meaningful candidate screening automation or AI recruitment screening for engineering roles, and building an automated hiring process on keyword logic alone is how teams end up with shortlists full of resume-optimized candidates who cannot pass a technical interview. The question is not whether to use an ATS, but which layer of actual technical evaluation to add on top of it.
Evaluation criteria for candidate screening automation
When evaluating screening tools — including AI screening for developers specifically — the most diagnostic criteria are less about feature lists and more about whether each capability holds up under your actual hiring conditions. Useful evaluation areas:
- Depth of code evaluation. Does the tool execute candidate code against test cases, or only check submission for keyword presence? Submission-only review will not differentiate a working solution from a non-functional one.
- Language and framework coverage. Verify support for the specific stack your team uses, not just headline language counts.
- Integration fit. Confirm specific ATS integration partners and the depth of sync (one-way, two-way, scheduling pass-through) with the vendor before signing.
- Assessment integrity controls. What is the vendor's approach to plagiarism detection, generative AI tool detection, and proctoring? Ask for documentation, not assurances.
- Compliance and audit support. Can the vendor provide bias audit documentation that will hold up under EEOC or NYC Local Law 144 review?
- Customization flexibility. Can you build assessments aligned to your tech stack, or are you constrained to a library that may not reflect your work?
Platform types compared
Three categories of pre-employment screening automation tools serve engineering hiring, and each has a defensible role depending on team needs. ATS platforms with built-in screening (such as Greenhouse, Lever, and Workday) are typically strongest on workflow orchestration: resume parsing, hiring stage routing, and basic knockout questions are tightly integrated with the rest of the talent stack, and many teams use them as the foundation for the rest of the screening layer. General-purpose assessment platforms (such as TestGorilla and iMocha) are typically used for breadth, with test libraries that span technical and non-technical skills — a useful fit when a hiring team is screening across mixed role types. Dedicated technical assessment platforms (such as HackerEarth and Codility) focus on engineering-specific depth, including developer-focused question libraries, real code execution environments, and scoring calibrated to engineering skill levels.
Within that dedicated-platform category, HackerEarth's Skill Assessments library spans 1,000+ skills across 40+ programming languages, with role-based assessments for frontend, backend, data, and DevOps work — useful when you need a specific framework or stack covered rather than a generic algorithm test. Each category has different strengths, and the choice depends on whether your team needs orchestration breadth, skill-library breadth, or engineering depth as the primary lever.
Note on competitor mentions: Product names above are illustrative of category positioning. Confirm feature parity directly with each vendor; capabilities change frequently.
Questions to ask during evaluation
Before committing to a platform, get direct answers to these:
- Does the platform support live code execution with test-case scoring, not just submission review?
- How does it detect AI tool use and plagiarism during assessments?
- Can I build custom assessments for our tech stack, or am I limited to library questions?
- What bias audit documentation can the vendor provide for compliance purposes?
- Which ATS systems does it natively integrate with, and at what level (one-way sync, two-way sync, scheduling)?
For an applied view of how teams stitch these together, see HackerEarth's guide to building a technical hiring funnel for the architecture pattern of using a dedicated technical platform alongside an existing ATS.
Step 3: Build skills-based assessments for automated screening
A well-designed workflow treats the assessment as the core evaluation instrument in your automated candidate screening process, not a checkbox after the resume screen. The assessment is where you separate candidates who understand the concept from candidates who can implement it.
Choose the right assessment format
Different formats reveal different things. Use the right one for what you are actually trying to measure:
Algorithmic coding challenges test problem-solving speed, data structure fluency, and language command. Useful for backend, infrastructure, and data engineering roles where performance optimization matters.
Multiple-choice questions (MCQs) screen foundational knowledge of languages, frameworks, and computer science concepts at scale. Useful as a first-pass filter before requiring candidates to invest time in a coding challenge.
Project-based assessments ask candidates to build or extend a piece of software resembling actual work. They produce the richest signal for senior roles where architecture and code quality matter more than algorithmic speed.
Pair programming simulations evaluate collaborative problem-solving, useful for teams where working in context matters as much as raw output.
Calibrate difficulty to role level
Mismatched difficulty is one of the most common sources of false negatives when you automate candidate screening. Running the same coding assessment for junior and senior candidates produces calibration errors at both ends of the skill spectrum. A screening assessment that asks a senior engineer to reverse a linked list will not tell you whether they can design a distributed caching layer. A junior developer assessment that opens with a system design challenge will produce high abandonment rates and misleading results.
A practical difficulty framework by seniority:
Junior (0-2 years): language fundamentals, basic data structures, simple API calls. Example: a DOM manipulation task for a frontend role, or a basic database CRUD operation.
Mid-level (3-5 years): applied problem-solving, framework-specific implementation, debugging a provided codebase, API integration. Example: a REST API endpoint with auth and validation.
Senior (6+ years): system design judgment, performance optimization, code review, architecture trade-offs. Example: design a rate-limiting service or optimize a slow database query with a 100K-row dataset.
Avoid the generic assessment trap
A Python developer applying for a data engineering role and a Python developer applying for a backend API role share a language but not a skill set. Sending them the same screening assessment produces a noisy signal for both.
Role-based assessments improve shortlist quality and reduce false negatives: strong candidates who are not optimized for generic algorithm tests will perform better on challenges that reflect the actual role.
For guidance on online coding interview platforms and how to build live interview components alongside async screening, see HackerEarth's FaceCode, a live coding interview tool that pairs real-time code execution with structured interviewer scorecards.
Step 4: Automate resume and application parsing for candidate screening
Resume parsing is the first filter when you automate candidate screening, and it is also the one most likely to fail candidates unfairly if it is built on keyword matching alone.
How AI resume parsing works
Modern resume parsing uses natural language processing (NLP) to extract structured data from unstructured resume text. In this context, "AI-powered" means the parser is built on NLP models trained to recognize skills, certifications, project descriptions, employment history, portfolio links, and educational credentials across the wide variation of formatting and phrasing candidates use; its limits include sensitivity to resume formatting, dependence on training-data recency, and reduced accuracy on PDFs with embedded images that are not legible to text extraction.
The practical output is a pre-filtered candidate pool sorted by technical relevance. Instead of starting a screening session with hundreds of equal-weight applications, the engineering lead sees the top 50 ranked by their actual match to the role requirements. Semantic parsers also handle the failure modes of pure keyword matching: a candidate who writes "built real-time data processing pipelines using Spark and Kafka" is not filtered out because they did not include the words "Apache" or "streaming," since the model understands those technologies are related. Skills-based screening can also reduce demographic bias by evaluating what candidates have done rather than how they have labeled it.
Configuring parsing for engineering reqs
Out-of-the-box parsers tend to be calibrated to generalist hiring. For engineering reqs, a few configuration choices materially change shortlist quality:
- Map your required skills to parser tags. Most parsing tools allow you to define synonyms and related-skill clusters (e.g., "Postgres" maps to "SQL," "RDBMS," and "relational databases"). Without this, candidates who use different conventions in their resumes get penalized for vocabulary, not substance.
- Weight project descriptions over self-reported skill lists. A resume's "Skills" block is a list of claims; the project section is where the work is described. Configure the parser to weight the latter more heavily.
- Set seniority signals beyond years of experience. Tenure does not equal seniority. Use signals like leadership scope, project complexity, and open-source contribution as additional inputs where the parser supports it.
- Integrate parser output with your ATS. Confirm the parser writes structured fields back to the ATS candidate record so downstream stages (assessment scoring, interviewer notes) reference the same underlying data.
Step 5: Add AI interview screening to your automated workflow
Resume parsing and coding assessments filter for technical competency. The next layer is automated interview screening: understanding how candidates think through problems and communicate their approach, qualities that matter in engineering teams but do not show up in code output alone.
What AI interview screening looks like
AI interview screening presents candidates with technical scenarios or problems and evaluates their responses along multiple dimensions: correctness of approach, code quality if applicable, clarity of explanation, and reasoning process. Candidates complete these asynchronously on their own schedule, which eliminates the scheduling bottleneck of coordinating live interviews for 50+ candidates.
The output is a structured evaluation report per candidate, scored consistently across the full cohort, so the hiring manager sees comparable data rather than notes from interviewers with different standards.
When to use async vs. structured AI interviews
Async AI interviews are appropriate for early-stage, high-volume screening where the goal is efficient filtering before any engineering time is committed. They work well for initial technical communication screening, basic problem-solving evaluation, and candidate ranking across large cohorts. Structured AI interviews that simulate a real interview conversation are more appropriate for mid-stage screening, where the format can probe a candidate's reasoning more deeply than a static MCQ or one-shot coding task. The intent is to surface a richer signal before a human interviewer's time is committed, not to replace human judgment in later rounds.
The common failure mode at this stage is that async one-shot recordings cannot probe a candidate's reasoning when their first answer is incomplete, and standalone structured interviews from generalist vendors often lack identity verification, leaving teams unsure whether the person being interviewed is the same person who applied. HackerEarth OnScreen was built to close that specific gap: it conducts rigorous, structured technical interviews around the clock using lifelike avatars with built-in identity verification and proctoring, applies a deterministic evaluation framework so each candidate is assessed against the same defined criteria, and uses KYC-grade candidate identity verification to confirm the person being evaluated is who they claim to be. The result is a shortlist of candidates who have demonstrated technical competence through a structured interview — not just a scored coding submission — so human interviewers can focus on later-stage judgment rather than early-round screens.
Step 6: Implement anti-cheating and fairness safeguards in automated screening
An automated screening process that can be gamed or that produces biased outcomes is worse than a slow manual process, because it creates false confidence in results that may be neither valid nor defensible.
Anti-cheating measures
Effective remote proctoring for online assessments layers multiple signals rather than relying on any single measure:
- Browser lockdown prevents candidates from switching to search engines or AI tools during the assessment
- Webcam monitoring uses computer vision to detect signs of unauthorized assistance
- Plagiarism detection compares each submission against known published solutions and other submissions in the cohort
- Randomized question pools ensure candidates in the same batch receive different questions, preventing answer sharing
- IP and device tracking flags multiple submissions from the same network
Communicate proctoring measures to candidates before the assessment begins. Transparent disclosure reduces candidate anxiety, improves completion rates, and prevents the employer brand damage that comes from surprise monitoring.
Bias mitigation in AI screening
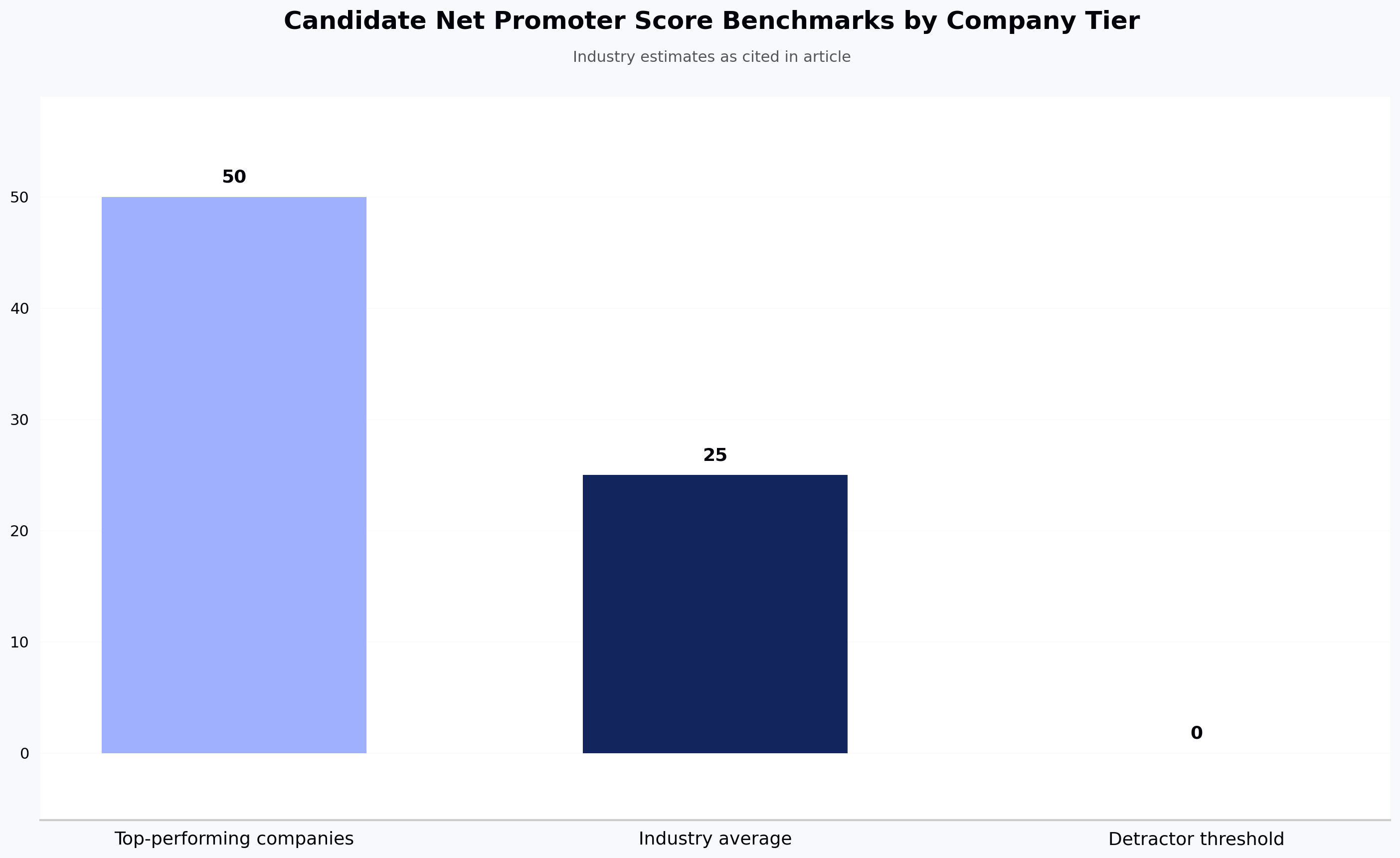
The EEOC's May 2023 technical assistance document makes clear that automated employment decision tools are subject to adverse impact analysis and job-relatedness requirements under Title VII. Practically, this means three things: audit, blind, and document.
Audit your AI screening tools regularly for demographic bias using built-in pass-rate reporting. NYC Local Law 144, which took effect for enforcement on July 5, 2023, requires annual independent bias audits for automated employment decision tools used in NYC hiring; confirm current applicability with counsel before relying on this. The EU AI Act classifies tools used for employment decisions as high-risk under Annex III, with phased obligations rolling out through 2026 and 2027 including documentation, transparency, and risk-management requirements. Implement blind screening that removes names, schools, and demographic identifiers from the scoring view, and document the link between each screening criterion and a specific job task. That documentation is your primary EEOC defense if outcomes are ever challenged.
Regulatory note (current as of 2025): The legal claims above reflect publicly available guidance at the time of writing and are not legal advice. Confirm current obligations with counsel before relying on them.
Step 7: Analyze results and shortlist candidates through automated screening
The output when you automate candidate screening well is a ranked candidate list built on multiple evaluation dimensions. The goal of this step is to translate that data into a shortlist without requiring a human to manually review every submission.
Automated scoring and ranking
Automated candidate evaluation compiles resume relevance, coding assessment scores (correctness, efficiency, code quality), and interview screening scores into a single composite ranking. This reduces the over-indexing problem: a candidate who aces the coding challenge but cannot explain their approach ranks differently from one who shows strong technical reasoning with slightly lower execution scores, and both signals matter.
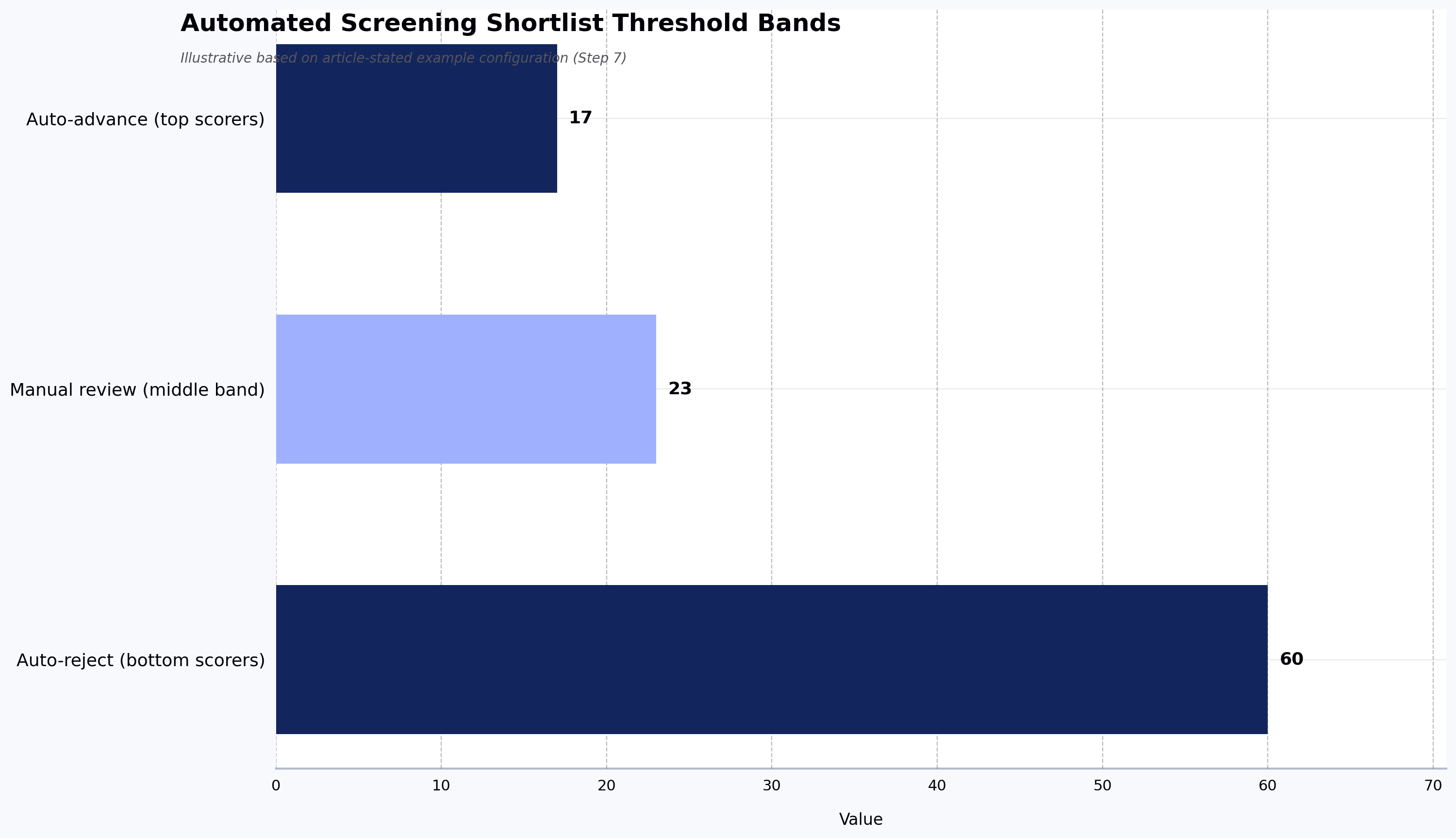
Set shortlist thresholds
Configure auto-advance and auto-review thresholds before the results come in. One example configuration — to use as an illustrative starting point, not a benchmark — might be:
- Top 15-20% by composite score: auto-advance to the next stage
- Middle 20-25%: manual review by a recruiter or engineering lead before a decision
- Bottom 55-65%: auto-reject with candidate notification
Calibrate the exact bands to your own historical pass-through data. The middle band is where human judgment adds the most value. Strong candidates with non-standard profiles sometimes land in this range for reasons unrelated to actual ability (unusual background, assessment type mismatch, or a single weak section dragging down an otherwise strong profile). A human review of this band catches the false negatives that pure automation would miss.
Dashboard reporting
A screening dashboard that shows the full cohort picture lets you improve the process with each hiring cycle. Useful metrics to track:
- Pass rates and score distributions by role and assessment type
- Assessment completion rates and drop-off points by stage
- Correlation between screening scores and downstream interview pass rates
If completion rates are low, the assessment is too long or poorly communicated. If every top-band candidate fails the live interview, the scoring thresholds or assessment design needs adjustment.
Step 8: Optimize your automated candidate screening workflow continuously
The platforms used to automate candidate screening are not set-and-forget systems. An assessment that screened well 18 months ago may now have its questions circulating on developer forums, or may have been calibrated against a candidate pool that no longer reflects your applicant base.
Treat the workflow as a feedback loop with quarterly review cycles:
- Track the screening-to-hire ratio: of candidates who pass automated screening, what percentage receive offers?
- Monitor quality-of-hire correlation: do high scorers perform well at the 90-day review?
- A/B test assessment types and time limits to find configurations with the best signal-to-completion trade-off
- Collect feedback from hiring managers on shortlist quality after each cycle and adjust thresholds accordingly
For guidance on the broader hiring funnel that feeds into this screening workflow, see HackerEarth's resources for engineering recruiters and hiring managers.
Where automated candidate screening performs poorly
Automation is not the right answer for every engineering hire, and treating it as a universal solution produces predictable failures. Cases where a more manual or hybrid approach typically performs better:
- Niche or specialist roles with small applicant pools. When a role attracts 12 applications rather than 400, the cost of careful manual review is low and the risk of automated false negatives is high. A single missed candidate is a larger percentage of the pool.
- Highly creative or research-oriented engineering roles. ML research positions,