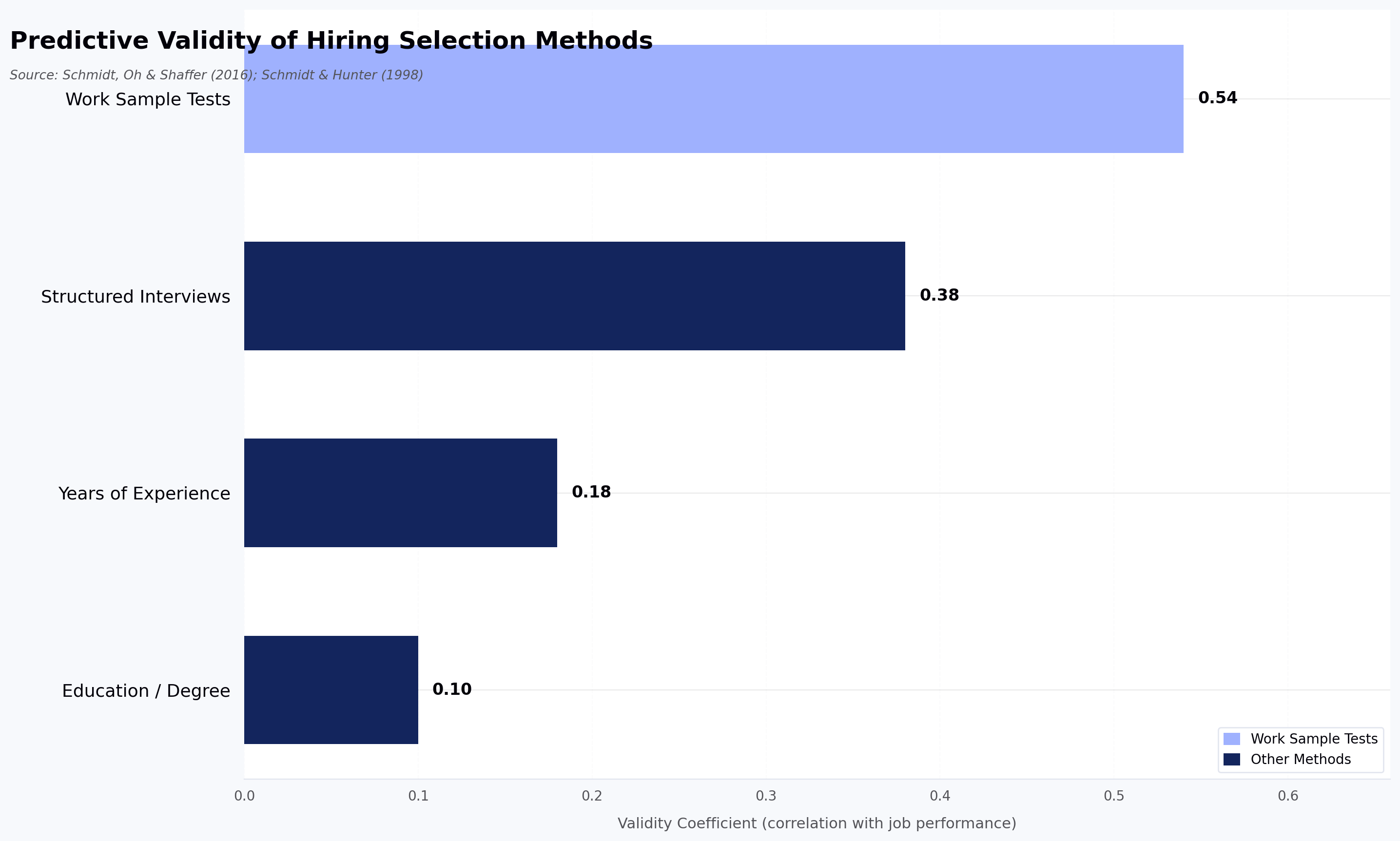
Most QA automation interviews test the wrong things. On one hand, candidates are increasingly using AI to shape their applications. iHire’s 2024 survey found 17.3% of job seekers used AI to write a resume or cover letter, up from 2.8% in 2023.
On the other hand, employers are evaluating AI-assisted candidates with generic screens, while candidates can easily use generative AI to answer standard Selenium questions. The result is resume keyword inflation, where every applicant lists Selenium, TestNG, Cucumber, and Jenkins, but recruiters still cannot tell who has built a production-grade automation framework versus who only completed a tutorial.
That is why a purpose-built AI interview agent matters. It shifts screening from keyword matching to live evaluation of real automation skills. This guide shows how HackerEarth’s AI Interview Agent applies structured rubrics, adaptive follow-ups, real-time code evaluation, and proctoring to screen QA automation candidates more accurately.
Why QA Automation Hiring Is Broken (And Why Generic AI Tools Don't Fix It)
Open any QA automation job listing, and you will receive hundreds of applications that look functionally identical. Every candidate claims expertise in Selenium WebDriver, proficiency with TestNG or JUnit, familiarity with Cucumber BDD, and hands-on experience with Jenkins pipelines.
Your recruiters cannot distinguish between a candidate who designed and maintained a scalable Page Object Model framework in production and one who followed a YouTube tutorial series last month. Without a structured, domain-specific evaluation layer, these resume keywords become noise that drains your team's screening hours without producing a reliable signal.
Where Do Most AI Tools Go Wrong?
Many AI interview platforms available today do not address this disconnect. They focus on behavioral interview questions or general algorithmic coding challenges, the kind of problems you'd find on competitive programming sites. These tools can verify whether a candidate writes syntactically correct Python.
They cannot evaluate whether that same candidate understands how to architect a test framework, can diagnose a StaleElementReferenceException in a CI pipeline, or knows the practical difference between a fluent wait and an explicit wait.
For QA automation hiring specifically, the gap between what generic tools assess and what the job actually requires makes AI-assisted screening feel no more useful than random filtering.
The situation worsens when you factor in candidate-side AI use. QA automation engineers are technically proficient enough to paste a Selenium scripting prompt into ChatGPT and receive a working, well-commented answer within seconds.
If your AI interview tool relies on static question banks with predictable coding exercises, you are measuring the quality of the candidate's AI assistant. This dynamic turns every static coding assessment into a test of prompt engineering.
How does a domain-specific AI interview agent help?
A domain-specific AI interview agent takes a fundamentally different approach. It decomposes QA automation evaluation into discrete skill dimensions, deploys adaptive follow-up questions that require genuine real-time technical reasoning, and simultaneously evaluates code quality across correctness, maintainability, and readability.
Building a structured interview process around these capabilities replaces keyword-based guesswork with competency-based evidence. The question is: what exactly does the AI evaluate, and how deep does it go?
The Seven QA Automation Skill Dimensions an AI Interview Agent Evaluates
A well-designed AI interview agent does not treat QA automation as a single, monolithic skill to be scored as a single number. Instead, it decomposes the role into discrete, measurable competency dimensions that map directly to what your QA engineers do every day on the job.
HackerEarth's AI Interview Agent evaluates candidates across these seven dimensions, drawing from a technical assessment library of 25,000+ curated questions spanning 1,000+ skills to generate a structured, dimension-by-dimension scorecard with scoring rationale for every assessment point.
1. Selenium WebDriver Core Competency
This dimension covers the fundamentals every QA automation engineer must demonstrate: locator strategies (CSS selectors, XPath, relative locators, and chained locators), browser interaction patterns, dynamic element handling, and WebDriver architecture. The AI starts with practical scenarios. A candidate who mentions XPath will face follow-up questions about when XPath is the wrong choice, what alternatives offer better performance, and how they handle locator stability in rapidly changing UIs.
2. Test Framework Architecture and Design Patterns
Framework design is what separates production-ready QA engineers from tutorial followers. The AI evaluates understanding of Page Object Model implementation, factory patterns, test data management strategies, and the ability to architect a framework that scales to hundreds of test cases without becoming brittle. Scenario-based questions probe why the candidate chose specific design patterns for specific situations.
3. Synchronization and Wait Strategies
Timing issues cause more flaky tests than any other single factor in Selenium automation. This dimension assesses whether candidates understand the practical differences between implicit, explicit, fluent, and custom waits. It also evaluates their ability to handle AJAX-heavy applications and dynamic content loading. The AI presents debugging scenarios containing code snippets with timing-related failures and evaluates the candidate's diagnostic approach step by step.
4. CI/CD Pipeline Integration
The AI also evaluates candidates on Jenkins and GitHub Actions configuration for test execution, parallel test execution strategies, containerized browser environments using Docker, and how to design a test suite that provides fast feedback loops without becoming a pipeline bottleneck. Candidates who claim CI/CD experience are asked how they triage a test that passes locally but fails consistently in the pipeline.
5. Cross-Browser and Cross-Platform Testing Strategy
This dimension goes beyond knowing that Selenium Grid exists. The AI assesses understanding of Grid architecture and hub-node configuration, cloud testing platform integration with services such as BrowserStack or Sauce Labs, mobile web testing considerations, and handling browser-specific rendering differences in test assertions.
Candidates with real cross-platform experience can articulate the tradeoffs between running a self-hosted Grid and using a cloud provider at scale.
6. Debugging and Failure Analysis
When a test fails at 2 AM in the CI pipeline, your QA engineer needs to diagnose it quickly. The AI evaluates exception-handling strategies, implementation of screenshot and log capture, root-cause analysis methodology, and how candidates communicate findings to the development team. It presents real-world failure scenarios with stack traces and assesses whether the candidate can trace the failure back to a code change, an environment issue, or a genuine product defect.
7. Test Data Management and API-Layer Testing
Senior QA engineers understand the test pyramid and know that not every validation belongs in the UI layer. This dimension evaluates how candidates manage test data across environments, integrate API testing into their automation strategy, decide when to push validation from the UI layer down to the API or unit layer, and balance test coverage against execution speed.
A candidate who defaults to UI-level testing for everything reveals weak strategic thinking that no amount of Selenium syntax knowledge can compensate for.
How the AI Interview Agent's Adaptive Questioning Works
The seven skill dimensions define what gets evaluated. But the real differentiator is not the dimensions themselves. It is how the AI adapts its questioning in real time based on each candidate's responses. The adaptive questioning model determines whether that evaluation captures genuine expertise or rehearsed answers.
Evolving Line of Questioning
Traditional AI interview platforms pull questions from a fixed pool in a predetermined order. HackerEarth's AI Interview Agent takes a fundamentally different approach, evolving its line of questioning based on each candidate's responses in real time.
If a candidate demonstrates strong knowledge of explicit waits, the AI escalates to custom wait conditions and AJAX polling strategies. If a candidate struggles with basic locator strategies, the agent adjusts the difficulty downward to map their proficiency floor accurately.
This branching dialogue means no two QA automation interviews follow the same path, making it structurally impossible for candidates to prepare by memorizing a question bank.
Live Environment Tests
Candidates also write actual Selenium code in a live environment. The AI evaluates submissions across correctness, maintainability, security, and readability simultaneously.
QA automation roles require evaluating whether a candidate’s Page Object Model implementation follows clean abstraction principles or creates tightly coupled dependencies that will break at scale.
Multi-Dimensional Scorecard
After every interview, the AI generates a dimension-by-dimension scorecard that goes beyond a single numeric score. Each of the seven skill dimensions receives its own assessment, along with a written rationale explaining what the candidate demonstrated and where weaknesses appeared.
Your hiring manager sees exactly why a candidate scored at the 85th percentile in debugging but at the 50th percentile in CI/CD integration, rather than receiving a single opaque number that tells them nothing actionable.
Adaptive Follow-up Questioning
Smart Browser technology, tab-switch detection, audio monitoring, and extension detection form the proctoring layer. But adaptive follow-up questioning is the strongest anti-gaming mechanism. When a candidate provides a polished answer about Selenium Grid architecture, the AI immediately probes with a contextual follow-up: "Your Grid configuration uses four nodes.
How would you handle a scenario where one node consistently produces different test results than the others?" That kind of real-time, context-dependent dialogue requires genuine technical thinking that cannot be outsourced to ChatGPT mid-conversation.
Where AI Evaluation Excels and Where Human Judgment Is Still Essential
An AI interview agent delivers its strongest value where consistency, scale, and objectivity matter most. It evaluates foundational QA automation competency with zero variation between candidates, applies identical scoring rubrics at 2 PM and 2 AM, provides structured, comparable scorecards across all time zones, and saves your engineering team 15+ hours per week that would otherwise be spent on first-round interviews.
For filtering candidates who lack core Selenium knowledge, understanding of synchronization, awareness of framework design, or CI/CD competency, AI outperforms human interviewers in speed, consistency, cost, and objectivity.
But an honest evaluation of any AI interview tool requires acknowledging where it falls short today. Architectural judgment calls remain difficult for AI to assess reliably. Deciding when to invest in UI automation versus API testing for a specific product, designing a test data strategy for a microservices migration, evaluating whether a legacy test suite should be refactored or replaced, or balancing test coverage against pipeline speed in a resource-constrained sprint: these decisions depend on accumulated context that no question bank can fully replicate. As one senior QA lead noted on Reddit's r/ExperiencedDevs: "The AI was great for eliminating obviously unqualified candidates. It was terrible at distinguishing between the top 30%."
The optimal workflow uses both layers in sequence.
- Deploy the AI Interview Agent for the first 80% of your evaluation, establishing a reliable technical competency baseline across all seven QA automation dimensions.
- Then reserve FaceCode live coding interviews for the final 20%, where a senior QA engineer on your team evaluates architectural thinking, system design decisions, test strategy tradeoffs, and team collaboration dynamics in real time.
This combination gives you the AI's strengths in structured, scalable first-pass filtering while preserving human judgment where it genuinely adds irreplaceable value.
Implementing AI-Driven QA Automation Interviews in Your Hiring Workflow
Moving from manual QA screening to AI-driven evaluation does not require a multi-month implementation project. Here is a practical five-step workflow for getting started.
Step 1: Define Role Requirements
Identify which of the seven QA automation skill dimensions matter most for your open role. A mid-level Selenium engineer may need deep evaluation across WebDriver competency, synchronization, framework architecture, and cross-browser testing. A senior QA lead role likely requires heavier weighting on CI/CD integration, test data strategy, debugging methodology, and API-layer testing. HackerEarth's JD-to-test generation feature lets you upload a job description and auto-generate a role-specific assessment in minutes.
Step 2: Configure for Your Tech Stack
Your team may work with Selenium, Playwright, Cypress, and Appium, or a mix of multiple frameworks. Configure the AI evaluation to match the specific frameworks, languages, tools, and environments your role requires. HackerEarth supports 40+ programming languages and 1,000+ skills, so the assessment reflects your actual engineering environment.
Step 3: Integrate with Your ATS
Connect the AI Interview Agent to your existing applicant tracking system. HackerEarth integrates natively with Greenhouse, Lever, SAP SuccessFactors, iCIMS, Workable, and 10+ other platforms. A Recruit API is available for custom integrations. Scorecards and candidate reports flow directly into your system of record without creating a new data silo.
Step 4: Run and Review
The AI conducts evaluations autonomously. Candidates complete their interview on their own schedule, and your hiring manager receives a structured scorecard with dimension-level scoring and written rationale before they ever speak to the candidate. No engineering hours are consumed until a candidate has cleared the AI competency baseline.
Step 5: Measure and Optimize
Track four key metrics after implementation: time-to-hire reduction, interview-to-offer ratio, engineering hours saved per hire, and post-hire performance correlation with AI scores. These data points indicate whether the AI is filtering effectively and where you may need to adjust dimension weights or difficulty thresholds for specific roles.
Once your workflow is live, one question remains: what does this evaluation process look like from the candidate's perspective, and how can QA automation engineers prepare for it?
What QA Automation Candidates Should Know About AI Interviews
If you are sharing this guide with QA automation candidates (or if you are a QA engineer reading this yourself), here is what the evaluation actually looks like from the other side of the screen.
The AI interview agent evaluates your skills across the seven dimensions covered earlier in this guide: WebDriver core competency, framework architecture, synchronization strategies, CI/CD integration, cross-browser testing, debugging methodology, and test data management.
It is not a trivia quiz.
You will not be asked to recite the difference between findElement and findElements from memory. Instead, you will work through real-world scenarios that mirror the problems you solve on the job, write actual code in a live environment, and explain your reasoning as you go. The AI adapts its follow-up questions based on your responses, so the interview naturally finds your proficiency level.
Preparation matters, but the right kind of preparation matters more.
Focus on articulating why you make specific technical decisions, not just what those decisions are. Practice explaining your framework design choices, walking through your debugging methodology step by step, and describing how your test automation strategy fits into a CI/CD pipeline. HackerEarth's AI Practice Agent (Helix) lets you practice mock interviews with instant AI feedback, so you can calibrate your responses and identify blind spots before the real evaluation.
When the interview starts, you will interact with a lifelike video avatar in a conversational format. The evaluation scores you on genuine skill across multiple competency dimensions, not on keyword density, verbal polish, or how confidently you present rehearsed answers. Candidates with real production experience consistently perform well because the adaptive questioning rewards depth of understanding over surface-level familiarity.
The Regulatory Context: Why Explainable AI Evaluation Matters
Your legal and compliance teams will eventually ask a pointed question about any AI interview tool you adopt: Can you explain and defend every hiring decision the AI influenced?
Regulatory requirements are making this question unavoidable. New York City's Local Law 144, effective since July 2023, requires independent bias audits of automated employment decision tools and mandates that employers notify candidates when AI is used in their evaluation. The EU AI Act, which took effect in August 2024, classifies AI used in hiring as "high-risk," requiring conformity assessments, human oversight mechanisms, and transparency documentation. These are current obligations for companies hiring in those jurisdictions.
HackerEarth supports compliance through structural design. Structured scorecards with dimension-by-dimension rationale create an audit trail that documents exactly what the AI evaluated, how it scored each competency, and why it reached its conclusions. PII masking removes bias-triggering personal information entirely from the evaluation process. ISO 27001, 27017, 27018, and 27701 certifications, combined with participation in the EU-US Data Privacy Framework, meet the security and data governance standards that enterprise procurement teams require before approving any AI tool that handles candidate data.
Conclusion
When evaluating an AI interview tool for QA automation roles, prioritize four capabilities: domain-specific question depth, adaptive follow-up questioning, structured scorecards, and regulatory-compliance infrastructure that meets your legal and procurement teams' requirements.
The right tool should reduce your engineering team's interview burden without sacrificing the evaluation rigor that distinguishes a production-ready QA engineer from a tutorial follower. If the AI cannot clearly explain why it scored a candidate the way it did, it will not survive your first compliance audit or your first skeptical engineering manager.
HackerEarth's AI Interview Agent evaluates QA automation candidates across all seven competency dimensions covered in this guide, drawing from 25,000+ curated questions and insights from 100M+ assessment signals to generate dimension-level scorecards with written rationale for every evaluation point.
The distance between what generic AI tools evaluate and what QA automation roles actually demand will only widen as test frameworks, CI/CD pipelines, and browser environments grow more complex.
Organizations that invest in domain-specific AI evaluation now will build a compounding advantage in hiring speed, evaluation consistency, and engineering team productivity. See how HackerEarth's AI Interview Agent evaluates QA automation skills in your specific hiring context. Try HackerEarth out now.
FAQs
1. Can an AI interview tool replace human recruiters entirely?
No. AI interview tools automate structured first-pass technical screening and scoring, but human recruiters remain essential for candidate relationship building, offer negotiation, and evaluating cultural alignment within your hiring teams.
2. Do AI interview tools introduce bias into the hiring process?
Well-designed platforms reduce bias by applying identical evaluation criteria to every candidate, masking personally identifiable information, and generating structured scorecards that remove subjective judgment from the initial screening stage.
3. How much does a typical AI interview tool cost for employers?
Pricing varies widely, from $99 per month for entry-level plans with limited interview credits to custom enterprise agreements based on hiring volume, integration requirements, and dedicated support needs.
4. Can AI interview tools handle assessments in multiple programming languages?
Leading platforms support 30 to 40 or more programming languages, allowing candidates to complete coding evaluations in the language most relevant to their role and your engineering team's technology stack.
5. What is the difference between an AI interview tool and a standard video interview platform?
AI interview tools actively evaluate candidate responses, generate structured scores, and adapt questions in real time, whereas standard video platforms simply record conversations without providing automated technical assessment.